背景介绍
在有些镜像包比较大,下载比较耗时的情况下,我们可以采用该方法,从一个网速(或代理)快的地方下载下来,再复制到其他地方去使用。
导出
1 | docker save alpine:latest > ./alpine_latest.tar |
远程复制
1 | # 指定端口号复制 |
导入
1 | docker load < ./alpine_latest.tar |
在有些镜像包比较大,下载比较耗时的情况下,我们可以采用该方法,从一个网速(或代理)快的地方下载下来,再复制到其他地方去使用。
1 | docker save alpine:latest > ./alpine_latest.tar |
1 | # 指定端口号复制 |
1 | docker load < ./alpine_latest.tar |
准备往docker容器中新增一个服务Z,但是服务Z对docker以及docker-compose版本要求较高,所以决定做一次升级。
简单看了下系统参数:
1 | $ uname -r |
貌似可以支持升级docker。
于是我首先运行了yum update 或者 yum upgrade(具体是哪个,我不记得了。这中间可能有error,当时没在意,起初我也不知道update和upgrade的区别)。
yum update和yum upgrade的真正区别:“yum update和yum upgrade的功能都是一样的,都是将需要更新的package更新到源中的最新版。唯一不同的是,yum upgrade会删除旧版本的package,而yum update则会保留(obsoletes=0)。生产环境中建议使用yum update,防止因为替换,导致旧的软件包依赖出现问题。”
然后按照docker官网教程升级了docker到版本:
1 | $ docker --version |
按照教程升级了docker-compose到版本:
1 | $ docker-compose --version |
一切顺利,兴高采烈的去将所有之前的docker服务运行起来,运行也一切正常,无任何报错。
但是,发现所有服务连不上了(我用的nginx做反向代理,转发请求道docker服务的),当时就很纳闷。
于是找运维帮忙排查,经过一阵子折腾,发现docker IP和宿主机IP有冲突了,于是就修改docker网段,改完之后现象和之前一样,服务能正常启动,就是连不上。于是一个一个排查:
systemctl stop firewalld最终发现几个问题:
应该能够确定问题:docker 加载内核的bridge.ko 驱动异常,导致docker0 网卡无法转发数据包,也就是系统内核的网桥模块bridge.ko 加载失败导致的,一般情况下这种场景的确很少见。
根据网上的说法是升级内核解决,于是我打算升级内核,运行:yum update,发现error:
1 | Error: initscripts conflicts with centos-release-7-2.1511.el7.centos.2.10.x86_64 |
于是又网上查找答案,发现是yum的配置文件里面禁止更新内核:
1 | $ cat /etc/yum.conf |
于是我注释掉排除升级内核的那一行,继续更新yum源仓库yum update就没有报错了:
1 | ... |
接下来就是按照这篇文章一步步操作升级内核。
升级完成,重启之后,发现yum报错:
1 | Cannot open logfile /var/log/yum.log |
解决方法将文件系统重新挂载为读/写:mount -o remount, rw /,注意“,”和“rw”之间有一个空格。
1 | # 使用 alpine 镜像创建一个容器,并进入容器 |
终于网络问题解决了😄。
为了避免IP冲突,最后又重新参考这里修改了docker网段。
1 | { |
问题是解决了,但是作为一个前端的我来说,还是有太多知识盲区,期间遇到了太多阻碍,不过解决之后很踏实,对网络、子网掩码有了更深的认识;对docker的认识也更加深刻。
在排查问题期间发现了一些好问题好文章:
centos >= 71 | sudo yum remove docker \ |
安装有多种方式,我们采用存储库(repository)方式进行安装(方便日后进行更新升级),这也是官方推荐的安装方式。
在安装之前,需要先配置安装源:
1 | sudo yum install -y yum-utils |
1 | sudo yum install docker-ce docker-ce-cli containerd.io |
1 | yum list docker-ce --showduplicates | sort -r |
指定版本安装
1 | sudo yum install docker-ce-<VERSION_STRING> docker-ce-cli-<VERSION_STRING> containerd.io |
1 | sudo systemctl start docker |
hello-world镜像来校验docker是否安装正确1 | sudo docker run hello-world |
升级和安装是一样的步骤,只是选择不同的版本进行安装,请先执行前提条件。
点击查看:阿里云官方镜像加速
常规操作:
1 | # 从远程克隆 |
注意,这将使存储库处于“分离头”状态。这意味着在此状态下所做的任何提交都不会影响任何分支。如果需要,可以使用-b 选项创建新分支:
1 | # 切换到指定tag并新建分支 |
快捷操作:克隆的时候添加-b参数指定 tag 即可。
1 | $ git clone -b <tagname> <repository> . |
但有时候项目过大,我们为了避免拉取(fetch)所有分支到本地,加上参数:–-single-branch,只拉取当前分支代码:
1 | $ git clone -b <tagname> –single-branch <repository> . |
如果我们只需要最后 1 条记录的话,可以使拉取(fetch)的数据量更小,加参数:--depth 1(该参数默认就是–-single-branch)
1 | $ git clone -b <tagname> –depth 1 <repository> . |
Web 指标是一组由 Google 定义的指标,用于衡量呈现时间、响应时间和布局偏移。每个数据点都提供有关应用程序整体性能的见解。
Sentry SDK 收集 Web 指标信息(如果浏览器支持的话)并将该信息添加到前端事务中。然后将这些重要信息汇总在几个图表中,以便快速了解每个前端事务对用户的执行情况。

这些 Web 指标被谷歌认为是直接衡量用户体验的最重要的指标。Google 报告称,截至 2021 年 5 月,这些指标也会影响网站的搜索排名。
最大内容绘制 (LCP)测量最大内容出现在视口中的渲染时间。这可以是来自文档对象模型 (DOM) 的任何形式,例如图像(images)、SVG 或文本块(text blocks)。视口中最大的像素区域,因此最直观。LCP 帮助开发人员了解用户看到页面上的主要内容需要多长时间。
首次输入延迟 (FID)测量用户尝试与视口交互时的响应时间。操作可能包括单击按钮(button)、链接(link)或其他自定义 Javascript 控制器。FID 提供有关应用程序页面上成功或不成功交互的关键数据。
累积布局偏移 (CLS)是渲染过程中每个意外元素偏移的单个布局偏移分数的总和。想象一下导航到一篇文章并尝试在页面完成加载之前单击链接。在您的光标到达那里之前,链接可能由于图像渲染而向下移动。CLS 分数代表了破坏性和视觉不稳定转变的程度,而不是使用持续时间来表示此 Web 指标。

使用影响和距离分数计算每个布局偏移分数。影响分数是元素在两个渲染帧之间影响的总可见区域。距离分数测量它相对于视口移动的距离。
1 | # Layout Shift Score = Impact Fraction * Distance Fraction |
让我们看一下上面的例子,它有一个不稳定的元素——正文内容。影响分数大约为页面的 50%,并将正文文本向下移动 20%。布局移位得分为 0.5 * 0.2 = 0.1。因此,CLS 为 0.1。
这些 Web 指标通常不太容易被用户看到,但对于排除核心 Web 指标的问题很有用。
首次渲染 (FP) 测量第一个像素出现在视口中所需的时间,呈现与先前显示内容相比的任何视觉变化。这可以是来自文档对象模型 (DOM) 的任何形式,例如背景颜色(background-color)、画布(canvas)或图像(image)。FP 可帮助开发人员了解渲染页面是否发生了任何意外。
首次内容绘制 (FCP)测量第一个内容在视口中呈现的时间。这可以是来自文档对象模型 (DOM) 的任何形式,例如图像、SVG 或文本块。FCP 经常与首次渲染(FP)重叠。FCP 帮助开发人员了解用户在页面上看到内容更新需要多长时间。
首字节时间(TTFB)测量用户浏览器接收页面内容的第一个字节所需的时间。TTFB 帮助开发人员了解他们的缓慢是由初始响应引起的还是由于渲染阻塞内容引起的。
谷歌定义的三个阈值:“好(GOOD)”、“需要改进(NEEDS IMPROVEMENT)”和“差(POOR)”用于将数据点分类为绿色、黄色和红色,用于对应的 Web 指标。“需要改进(NEEDS IMPROVEMENT)”在 Sentry 中被称为“Meh”。
| Web 指标 | 好 | 需要改进 | 差 |
|---|---|---|---|
| 最大的内容绘制(LCP) | <= 2.5s | <= 4s | > 4s |
| 首次输入延迟(FID) | <= 100ms | <= 300ms | > 300ms |
| 累积布局偏移(CLS) | <= 0.1 | <= 0.25 | > 0.25 |
| 首次渲染(FP) | <= 1s | <= 3s | > 3s |
| 首次内容绘制(FCP) | <= 1s | <= 3s | > 3s |
| 首字节时间(TTFB) | <= 100ms | <= 200ms | > 600ms |
一些 Web 指标(例如 FP、FCP、LCP 和 TTFB)是相对于事务的开始进行测量的。与使用其他工具(例如 Lighthouse )生成的值相比,值可能会有所不同。
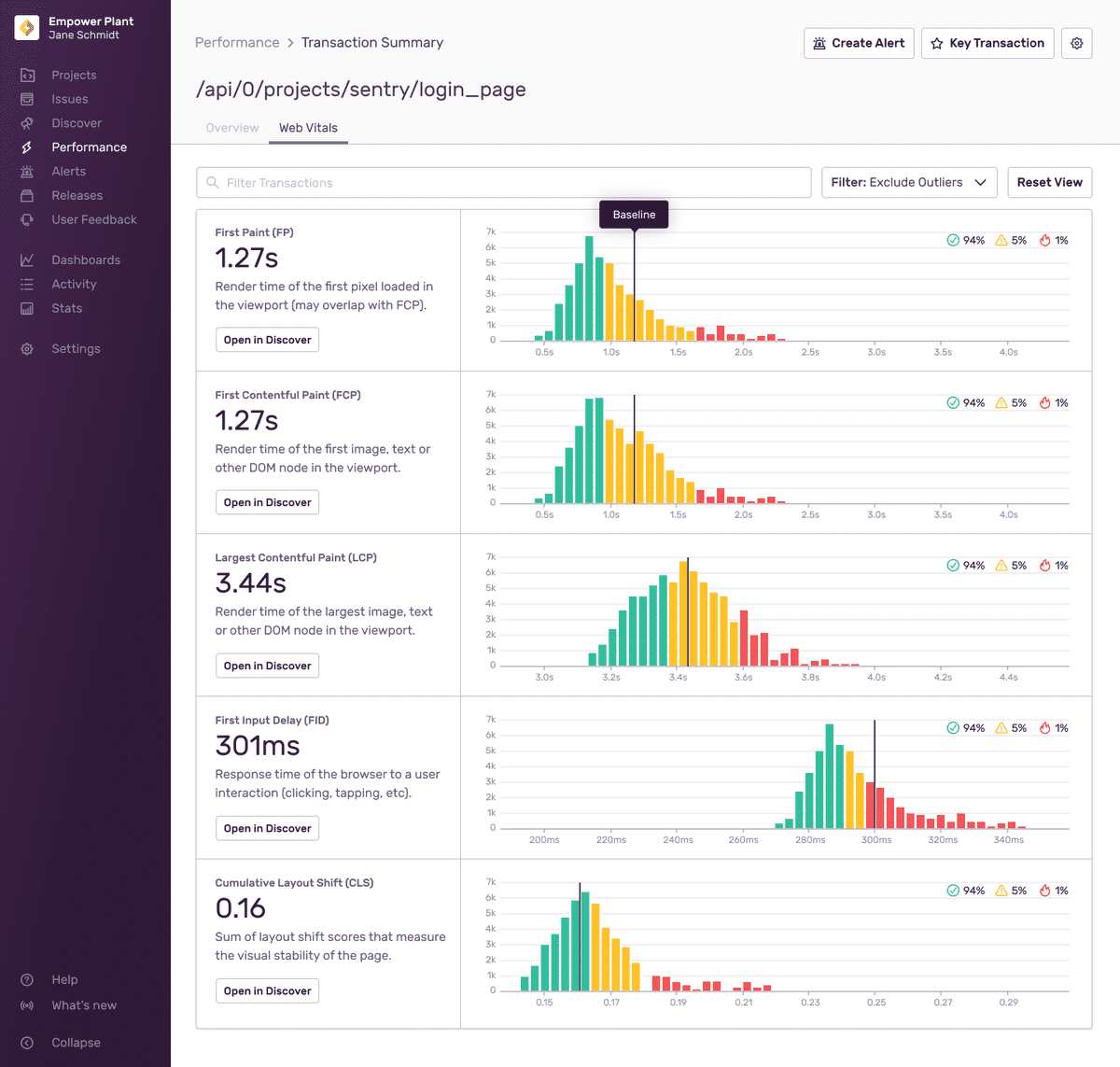
Web 指标直方图显示数据分布,它可以通过揭示异常来帮助您识别和诊断前端性能问题。
默认情况下,异常值将从直方图中排除,以提供有关这些生命体征的更多信息视图。异常值是使用上外栅栏(upper outer fence)作为上限来确定的,任何高于上限的数据点都被视为异常值。
每个 Web 指标的垂直标记是观察到的数据点的第 75 个百分位。换句话说,25% 的记录值超过了该数量。
如果您注意到任何直方图上的感兴趣区域,请单击并拖动放大该区域以获得更详细的视图。您可能还想在直方图中查看与事务相关的更多信息。单击所选 Web 指标下方的“在发现中打开(Open in Discover)”以构建自定义查询以进行进一步调查。有关更多详细信息,请参阅 Discover Query Builder 的完整文档。
如果您希望查看所有可用数据,请打开下拉菜单并单击“查看全部(View All)”。单击“查看全部”时,您可能会看到极端异常值。您可以单击并拖动放大某个区域以获得更详细的视图。
| Web 指标 | Chrome | Edge | Opera | Firefox | Safari | IE |
|---|---|---|---|---|---|---|
| 最大的内容绘制(LCP) | ✓ | ✓ | ✓ | |||
| 首次输入延迟(FID) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| 累积布局偏移(CLS) | ✓ | ✓ | ✓ | |||
| 首次渲染(FP) | ✓ | ✓ | ✓ | |||
| 首次内容绘制(FCP) | ✓ | ✓ | ✓ | ✓ | ✓ | |
| 首字节时间(TTFB) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
原文:Web Vitals
该文档列出了比较容易违反、比较重要的几个规则,更多规则请查看:sonar rules for js
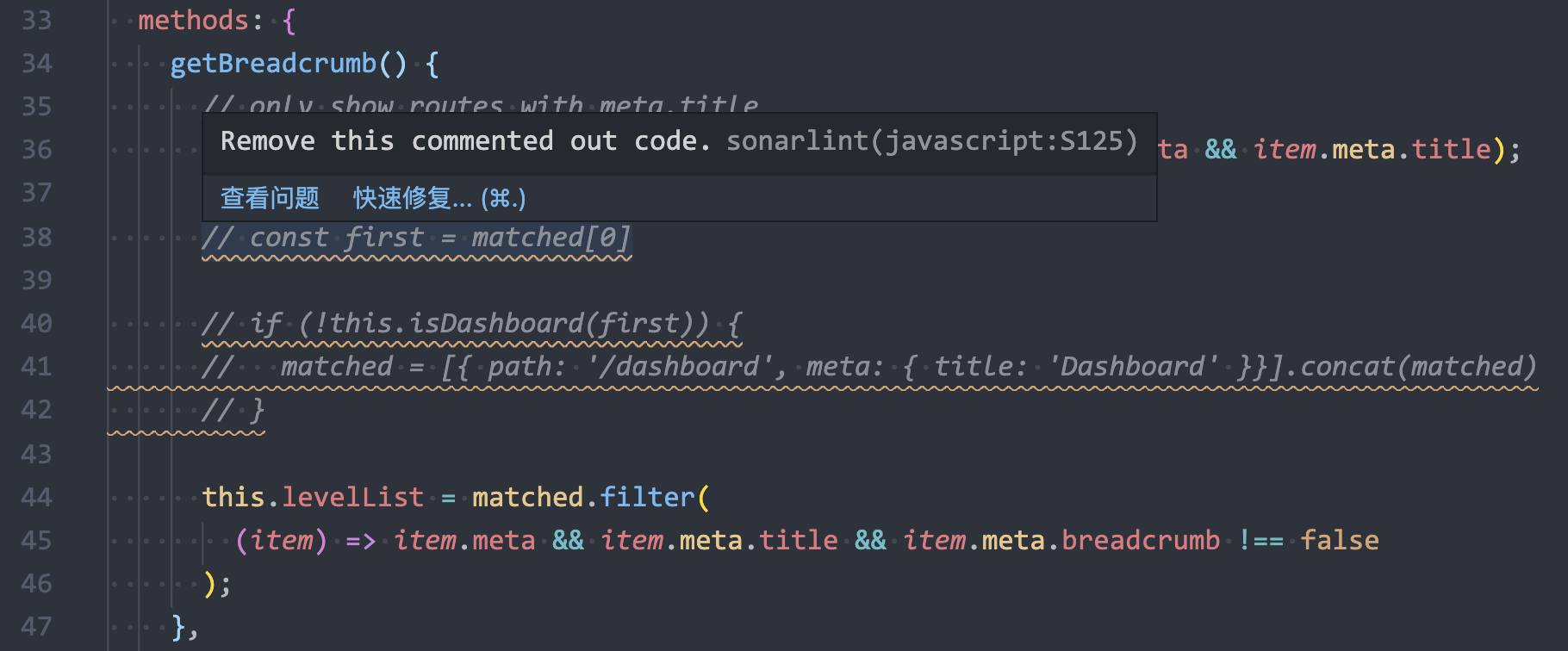
程序员不应注释掉代码,因为它会使程序膨胀并降低可读性。未使用的代码应该被删除,如果需要,可以从源代码控制历史(如:Git History)中检索。
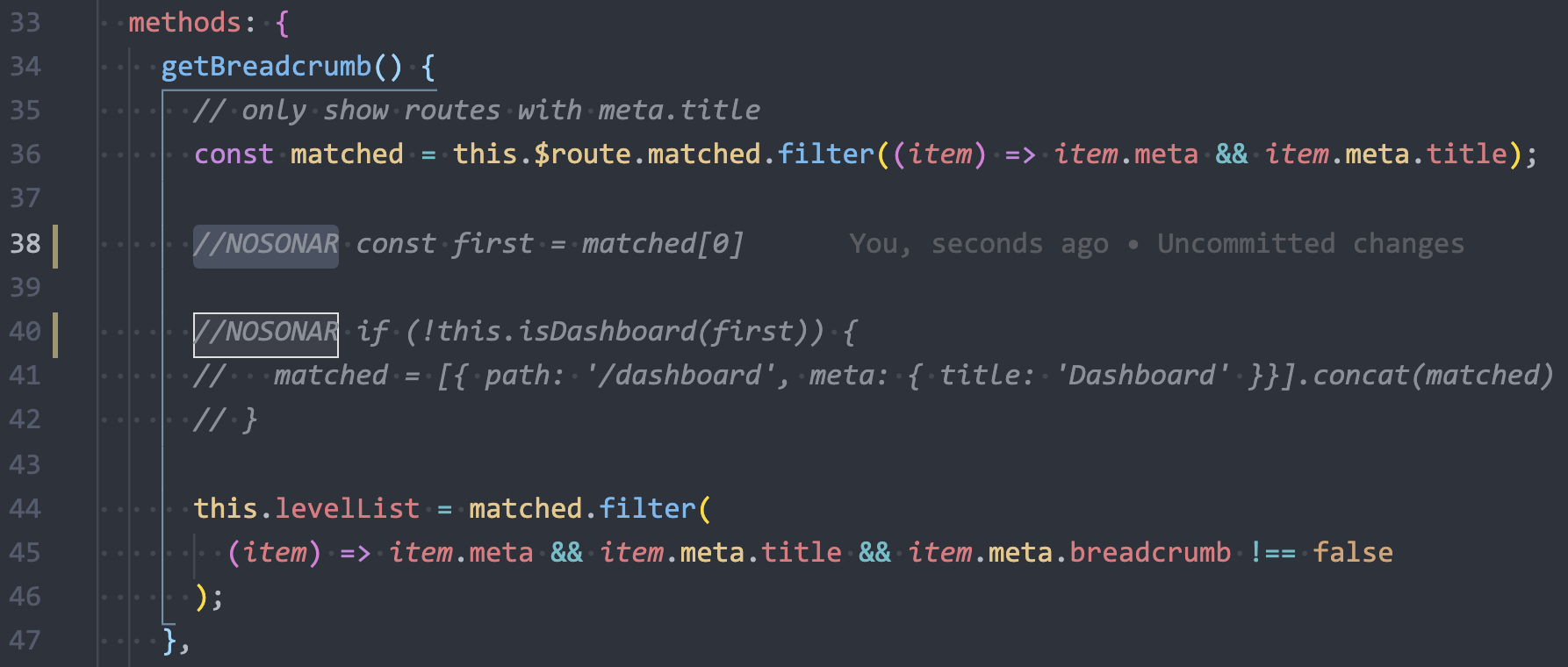
有些情况可能会误报、不合理报错或者本来就是有用的注释,可以试试使用//NOSONAR来规避:
加上//NOSONAR,sonar扫描便会忽略掉,就不会再有警告:
认知复杂性是衡量函数控制流理解难度的指标。认知复杂度高的功能将难以维护。详情请看《认知复杂度(cognitive complexity )》
重写或隐藏在外部作用域中声明的变量会严重影响代码的可读性,从而影响代码的可维护性。此外,这可能会导致维护人员引入 bug,因为他们认为自己在使用某一个变量,但实际上在使用另一个变量。
三元运算符嵌套虽然可以解决问题,刚开始编写的时候看起来可能很清晰,但是随着时间延长会增加后期的维护难度。
反例:
1 | function getReadableStatus(job) { |
正例:
1 | function getReadableStatus(job) { |
定义了一个变量并对其进行了赋值操作,但实际上却未使用。可能是错误操作导致(比如代码删错),也可能是失误多写了。但总归是无用的,可以删除掉。
反例:
1 | i = a + b; // Noncompliant; calculation result not used before value is overwritten |
正例:
1 | i = a + b; |
例外情况:
-1, 0, 1, null, undefined, [], {}, true, false, ""的会被该规则忽略1 | let { a, b, ...rest } = obj; // 'a' and 'b' are ok |
如果您有一个可迭代对象,例如数组、集合或列表,则循环遍历其值的最佳选择是 for of 语法。 这可以使代码看起来更干净、清晰。
反例:
1 | const arr = [4, 3, 2, 1]; |
正例:
1 | const arr = [4, 3, 2, 1]; |
如果声明了局部变量或局部函数但未使用,则它是死代码,应删除。 这样做将提高可维护性,因为开发人员不会想知道变量或函数的用途。
反例:
1 | function numberOfMinutes(hours) { |
正例:
1 | function numberOfMinutes(hours) { |
当两个函数具有相同的实现时,要么是一个错误(有其他用途),要么重复是故意的,但可能会使维护者感到困惑。 在后一种情况下,应该重构代码。
反例:
1 | function calculateCode() { |
正例:
1 | function calculateCode() { |
函数没有函数体有几个原因:
反例:
1 | function foo() {} |
正例:
1 | function foo() { |
有些变量分配是没必要的,所以可以优化掉。
反例:
1 | a = b; |
正例:
1 | a = b; |
子表达式中的赋值很难被发现,因此降低了代码的可读性。 理想情况下,子表达式不应该有副作用。
反例:
1 | if ((val = value() && check())) { |
正例:
1 | val = value(); |
声明一个变量只是为了立即返回或抛出它是一种不好的做法。
一些开发人员认为这种做法提高了代码的可读性,因为它使他们能够明确地命名返回的内容。 然而,这个变量是一个内部实现细节,不会暴露给方法的调用者。 方法名称应该足以让调用者确切地知道将返回什么。
反例:
1 | function computeDurationInMilliseconds() { |
正例:
1 | function computeDurationInMilliseconds() { |
类似规则:条件结构中的所有分支不应具有完全相同的实现(All branches in a conditional structure should not have exactly the same implementation)
switch 语句中的两个 case 或 if 链中的两个分支具有相同的实现充其量是重复代码,最坏的情况是编码错误。 如果两个实例确实需要相同的逻辑,那么在 if 链中它们应该被组合,或者对于一个 switch,一个应该落到另一个。
反例:
1 | switch (i) { |
例外情况:
if 链中包含单行代码的块将被忽略,就像 switch 语句中包含单行代码(带有或不带有后续中断)的块一样。
1 | if (a == 1) { |
但是这个例外不适用于没有 else 的 if 链,或者当所有分支都具有相同的单行代码时没有 default 子句的 switch。 如果 if 链带有 else 或带有 default 子句的 switch,规则 {rule:javascript:S3923} 会引发错误。
1 | if (a == 1) { |
在比较表达式 == 和 != 中应避免使用布尔字面量,以提高代码可读性。此规则还报告冗余的布尔运算。
反例:
1 | let someValue = '0'; |
正例:
1 | if (someValue && someValue != '0') { |
跳转语句,例如 return、break 和 continue 可以让你改变程序执行的默认流程,但是将控制流引导到原始方向是多余的。
反例:
1 | function redundantJump(x) { |
正例:
1 | function redundantJump(x) { |
例外情况:
按照惯例,只导出一个类、函数或常量的文件应该以该类、函数或常量命名。 否则可能使维护者感到困惑。
反例:
1 | // file path: myclass.js -- Noncompliant |
正例:
1 | // file path: MyClass.js |
与强类型语言不同,JavaScript 不强制函数的返回类型。 这意味着通过函数的不同路径可以返回不同类型的值,这可能会让使用者感到非常困惑并且难以维护。
反例:
1 | // Noncompliant |
正例:
1 | function foo(a) { |
例外:返回 this 的函数将被忽略。
1 | function foo() { |
返回类型为 any 的表达式的函数将被忽略。
没有理由导入你不使用的模块,这样做不必要地增加了负载。
反例:
1 | // Noncompliant, A isn't used |
正例:
1 | import { B1 } from 'b'; |
void 运算符评估其参数并无条件地返回 undefined。 它在 ECMAScript 5 之前的环境中很有用, undefined 可以重新分配。但通常,它的使用会使代码更难理解。
反例:
1 | void doSomething(); |
正例:
1 | doSomething(); |
例外:当使用 void 0 代替 undefined 时不会出现问题。
1 | if (parameter === void 0) {...} |
在立即调用的函数表达式之前使用 void 时,也不会出现问题。
1 | void (function() { |
为函数参数定义默认值可以使函数更易于使用。默认参数值允许调用者根据需要指定尽可能多或尽可能少的参数,同时获得相同的功能并最大限度地减少样板(boilerplate)、包装器(wrapper)类似的代码。
但是所有带默认值的函数参数都应该在没有默认值的函数参数之后声明。否则,调用者就无法利用默认值;他们必须重新指定默认值或传递 undefined 以“获取”非默认参数。
反例:
1 | // Noncompliant |
正例:
1 | function multiply(b, a = 1) { |
当集合为空时,访问或迭代它是没有意义的。 无论如何这样做肯定是错误的。
反例:
1 | let strings = []; |
JavaScript 语言规范中指定了内置函数的参数类型。 对这些函数的调用应符合规定的类型,否则结果很可能不是预期的,例如:
反例:
1 | const isTooSmall = Math.abs(x < 0.0042); |
正例:
1 | const isTooSmall = Math.abs(x) < 0.0042; |
反转布尔比较增加了不必要的代码复杂度。应该进行相反的比较。
反例:
1 | if (!(a === 2)) { ... } // Noncompliant |
正例:
1 | if (a !== 2) { ... } |
当对函数的调用没有任何副作用时,如果结果被忽略,调用的意义何在? 在这种情况下,要么函数调用没用,应该删除,要么源代码没有按预期运行。
为防止产生任何误报,此规则仅在已知对象和功能的预定义列表上触发问题。
反例:
1 | 'hello'.lastIndexOf('e'); // Noncompliant |
正例:
1 | let char = 'hello'.lastIndexOf('e'); |
违反此规则的代码中,使用map进行循环的情况最多,如果不需要循环返回值,请使用forEach代替。
实际上,可以多次使用相同的符号作为变量或函数,但这样做可能会使维护者感到困惑。此外,这种重新分配可能是错误的,开发人员没有意识到变量的值被新的分配覆盖了。
此规则也适用于函数参数。
反例:
1 | var a = 'foo'; |
正例:
1 | var a = 'foo'; |
JavaScript 中的数组有几种(过滤、映射或折叠)需要回调的方法。在这样的回调函数中没有 return 语句很可能是一个错误,因为数组的处理使用了回调的返回值。 如果没有返回,回调将隐式返回 undefined,这可能会失败。
此规则适用于数组的以下方法:
Array.fromArray.prototype.everyArray.prototype.filterArray.prototype.findArray.prototype.findIndexArray.prototype.mapArray.prototype.reduceArray.prototype.reduceRightArray.prototype.someArray.prototype.sort反例:
1 | let arr = ['a', 'b', 'c']; |
正例:
1 | let arr = ['a', 'b', 'c']; |
违反此规则的代码中,使用map进行循环的情况最多,如果不需要循环返回值,请使用forEach代替。
使用严格相等运算符 === 和 !== 比较不同的类型将始终返回相同的值,分别为 false 和 true,因为在比较之前没有进行类型转换。因此,这种比较是错误的。
反例:
1 | var a = 8; |
正例:
1 | var a = 8; |
当同一个表达式的值有许多不同的情况时,switch 语句很有用。但是,对于一两种情况,使用 if 语句会使代码更具可读性。
反例:
1 | switch (variable) { |
正例:
1 | if (variable == 0) { |
当一个集合被填充但它的内容从未被使用时,那么它肯定是某种错误。要么重构使集合变得毫无意义,要么缺少访问权限。
当除了添加或删除值的方法之外没有对集合调用任何方法时,此规则会引发问题。
反例:
1 | function getLength(a, b, c) { |
正例:
1 | function getLength(a, b, c) { |
跳转语句,例如 return、break 和 continue 可以让你改变程序执行的默认流程,但是将控制流引导到原始方向的跳转语句是多余的。
反例:
1 | function redundantJump(x) { |
正例:
1 | function redundantJump(x) { |
例外:
switch 语句中的 break 和 return 被忽略,因为它们经常用于保持一致性。 continue with label 也会被忽略,因为标签通常用于清晰起见。 此外,块中作为单个语句的跳转语句也将被忽略。
异步函数总是将返回值包装在 Promise 中。 因此,使用 return await 是多余的。
反例:
1 | async function foo() { |
正例:
1 | async function foo() { |
任何没有副作用且不会导致控制流改变的语句(空语句除外,这意味着语句只包含一个分号;)通常会指示编程错误,因此应该重构。
反例:
1 | a == 1; // Noncompliant; was assignment intended? |
从上到下评估 if/else if 语句链。 最多只会执行一个分支:第一个条件为真的分支。
因此,复制条件会自动导致死代码。通常,这是由于复制/粘贴错误造成的。充其量只是死代码,最糟糕的是,它是一个错误,在维护代码时可能会引发更多错误,显然它可能导致意外行为。
请注意,此规则要求 Node.js 在分析期间可用。
反例:
1 | if (param == 1) |
正例:
1 | if (param == 1) |
2021 年 4 月 5 日,1.5 版本
圈复杂度(Cyclomatic Complexity)最初被表述为对模块控制流的“可测试性和可维护性”的度量。 虽然它擅长测量前者,但其基础数学模型在产生测量后者的值方面并不令人满意。本白皮书描述了一种新指标,它打破了使用数学模型来评估代码的方式,以弥补圈复杂度的缺点,并产生一种更准确地反映理解难度的度量指标,从而更准确地反映维护方法、类和应用程序的相对难度。
虽然认知复杂度是一种与语言无关的度量标准,它同样适用于文件(files)和类(classes),以及方法(methods)、过程(procedures)、函数(functions)等,但为了方便起见,使用了面向对象的术语“类(class)”和“方法(method)”。
Thomas J. McCabe 的圈复杂度长期以来一直是衡量方法控制流复杂度的事实标准。它最初的目的是“识别难以测试或维护的软件模块”[1],但虽然它准确计算了完全覆盖一个方法所需的最少测试用例数,但它并不是一个令人满意的可理解性度量。这是因为具有相同圈复杂度的方法不一定给维护者带来相同的难度,导致测量通过高估某些结构而低估其他结构的“假象”。
同时,圈复杂度不再是全面的。它于 1976 年在 Fortran 环境中制定,不包括现代语言结构,如try/catch和lambdas。
最后,因为每个方法的最小圈复杂度分数为 1,所以不可能知道任何具有高聚合圈复杂度的给定类是属于大型的、易于维护的类还是具有复杂控制流的小类。除了类级别之外,人们普遍认为应用程序的圈复杂度分数与其代码行总数相关。换句话说,圈复杂度在方法级别之上几乎没有用处。
作为这些问题的补救措施,认知复杂度(Cognitive Complexity)已被制定于解决现代语言结构,并在类和应用程序级别产生有意义的值。更重要的是,它脱离了基于数学模型评估代码的实践,因此它可以产生与程序员对理解这些流程所需的心理或认知相对应的控制流评估。
以它旨在解决的问题为例,开始讨论认知复杂性是很有用的。 以下两种方法具有相同的圈复杂度,但在可理解性方面却截然不同。
1 | // 示例1: |
圈复杂度(Cyclomatic Complexity)底层的数学模型赋予这两种方法同等的权重,但从直观上看,sumOfPrimes的控制流程比getWords的控制流程更难理解。 这就是为什么认知复杂度(Cognitive Complexity)放弃使用数学模型来评估控制流,转而使用一组简单的规则将程序员的直觉转化为数字。
认知复杂度分数根据三个基本规则进行评估:
此外,复杂性分数由四种不同类型的增量组成:
A. 嵌套(Nesting) - 评估在彼此内部嵌套控制流结构
B. 结构化(Structural) - 对受嵌套增量影响并增加嵌套计数的控制流结构进行评估
C. 基本(Fundamental) - 评估不受嵌套增量约束的语句
D. 混合(Hybrid) - 对不受嵌套增量影响但确实增加嵌套计数的控制流结构进行评估
虽然增量的类型在数学上没有区别 - 每个增量都会在最终分数上+1 - 区分正在计算的特征类别可以更容易地理解嵌套增量适用和不适用的地方。
这些规则及其背后的原则将在以下各节中进一步详述。
制定认知复杂度的一个指导原则是它应该激励良好的编码实践。也就是说,它应该忽略或忽略使代码更具可读性的功能。
方法结构本身就是一个很好的例子。将代码分解成方法允许您将多个语句压缩成一个单一的、令人回味的命名调用,即“简写”它。因此,方法的认知复杂度不会增加。
认知复杂度还忽略了在许多语言中发现的空合并运算符,同样是因为它们允许将多行代码简写为一行。 例如,以下两个代码示例执行相同的操作:
1 | // 示例1: |
示例 1 的含义需要一点时间来处理,而一旦您理解了空合并语法,示例 2 的含义就会立即清晰。 出于这个原因,认知复杂度会忽略空合并运算符。
认知复杂度的另一个指导原则是,(从上到下、从左到右的正常线性流程中的)破坏性代码结构会增加维护人员的理解难度。为了承认这种额外的努力,认知复杂度评估了以下方面的结构增量:
for, while, do while, ...三元运算符、if, #if, #ifdef, ...评估混合增量:
else if, elif, else, …它没有评估这些结构的嵌套增量,因为在阅读if时已经计算了认知成本。(No nesting increment is assessed for these structures because the mental cost has already been paid when reading the if.)
对于习惯了圈复杂度的人来说,这些增量目标似乎很熟悉。此外,认知复杂度也会增加:
Catches:
catch和if一样代表控制流中的一种分支。因此,每个catch子句都会导致认知复杂度的增加。请注意,无论catch到多少异常,catch都只会为认知复杂度增加 1 分。try和finally块被完全忽略。
Switches:
一个switch和它所有的case组合在一起会产生一个单一的结构增量。
在圈复杂度下,switch被视为if-else if 链的模拟。也就是说,switch中的每种情况都会导致增量,因为它会导致控制流的数学模型中出现分支。
但是从维护者的角度来看,一个switch —— 将单个变量与一组明确命名的文字值进行比较 —— 比 if-else if 链更容易理解,因为后者可以使用任意数量的变量和值进行任意数量的比较。
简而言之,if-else if 链(结构的代码)必须仔细阅读,而switch通常可以一目了然。
Sequences of logical operators(逻辑运算符序列):
出于类似的原因,认知复杂度不会因每个二元逻辑运算符而增加。相反,它评估每个二元逻辑运算符序列的基本增量。 例如:
1 | // 示例1: |
理解上述 2 个示例中的第二行并不比理解第一行难。 另一方面,理解以下两行却有显着差异:
1 | a && b && c && d |
因为混合运算符使布尔表达式变得更加难以理解,因此对于类似运算符的每个新序列,认知复杂度都会增加。 例如:
1 | if (a // +1 for `if` |
虽然认知复杂度为相对于圈复杂度的类似运算符提供了“折扣”,但它确实会增加所有二进制布尔运算符序列,例如变量赋值、方法调用和返回语句中的运算符。
Recursion(递归):
与圈复杂度不同,无论是直接的还是间接的,认知复杂度为递归循环中的每个方法添加一个基本增量。 这个决定有两个动机。 首先,递归代表一种“元循环”,并且循环的认知复杂度递增。其次,认知复杂度是关于估计理解一个方法的控制流的相对难度,甚至一些经验丰富的程序员也发现递归难以理解。
Jumps to labels(跳转标签):
goto为认知复杂度添加了一个基本增量,就像break或continue到标签和其他多级跳转,例如break或continue到某些语言中的数字。但是因为提前返回通常可以使代码更清晰,所以其他跳转或提前退出不会导致增量。
从直觉上看,五个 if 和 for 结构的线性系列比连续嵌套的五个相同的结构更容易理解,无论通过每个系列的执行路径的数量如何。 由于这种嵌套增加了理解代码的心理需求,因此认知复杂度评估了它的嵌套增量。
具体来说,每次导致结构或混合增量的结构嵌套在另一个这样的结构中时,每个嵌套级别都会添加一个嵌套增量。例如,在以下示例中,方法本身或try没有嵌套增量,因为这两种结构都不会导致结构性增量或混合增量:
1 | void myMethod () { |
但是,if、for、while 和 catch结构都受结构和嵌套增量的影响。
此外,虽然顶级方法被忽略,并且 lambdas、嵌套方法和类似功能没有结构增量,但当嵌套在其他类似方法的结构中时,这些方法确实会增加嵌套级别:
1 | void myMethod2 () { |
制定认知复杂度的主要目标是计算更准确地反映方法的相对可理解性的方法分数,其次要目标是解决现代语言结构并产生在方法层面上有价值的指标。显然,解决现代语言结构的目标已经实现。下面检查另外两个目标。
这个讨论从一对具有相同圈复杂度但明显不同的可理解性的方法开始。 现在是时候重新检查这些方法并计算它们的认知复杂性分数了:
1 | int sumOfPrimes(int max) { |
认知复杂度算法为这两种方法给出了明显不同的分数,这些分数更能反映它们的相对可理解性。
此外,由于认知复杂度不会因方法结构而增加,因此聚合数字变得有用。现在,您可以通过简单地比较它们的度量值来区分域类(具有大量简单的getter和setter的类)和包含复杂控制流的类之间的区别。因此,认知复杂度成为衡量类和应用程序相对可理解性的工具。
编写和维护代码的过程是人工过程。它们的输出必须符合数学模型,但它们本身并不适合数学模型。这就是为什么数学模型不足以评估它们所需的努力。
认知复杂度打破了使用数学模型来评估软件可维护性的做法。它从圈复杂度设定的先例开始,但使用人类判断来评估应该如何计算结构,并决定应该将什么添加到整个模型中。因此,它产生的方法复杂性分数让程序员觉得比以前的模型更公平的可理解性相对评估。此外,由于认知复杂度不收取方法的“入门成本”,因此它不仅在方法级别,而且在类和应用程序级别都会产生更公平的相对评估。
[1] Thomas J. McCabe, “A Complexity Measure”, IEEE Transactions on Software Engineering, Vol. SE-2, No. 4, December 1976
一个 YUI 的 js 示例:
1 | save: function (options, callback) { |
todo…
本节的目的是简要列举增加认知复杂度的结构和情况,但附录 A 中列出的例外情况除外。这是一个全面的列表,而不是详尽无遗的。也就是说,如果一种语言对关键字有一个非典型的拼写,例如elif和else if,这里的省略并不是为了从规范中省略它。
以下各项都有一个增量:
if, else if, else, 三元运算符switchfor, foreachwhile, do whilecatchgoto LABEL, break LABEL, continue LABEL, break NUMBER, continue NUMBER以下结构增加嵌套级别:
if, else if, else, 三元运算符switchfor, foreachwhile, do whilecatchlambda(nested methods and method-like structures such as lambdas)以下结构接收与它们在 B2 结构内的嵌套深度相称的嵌套增量:
if, 三元运算符switchfor, foreachwhile, do whilecatch