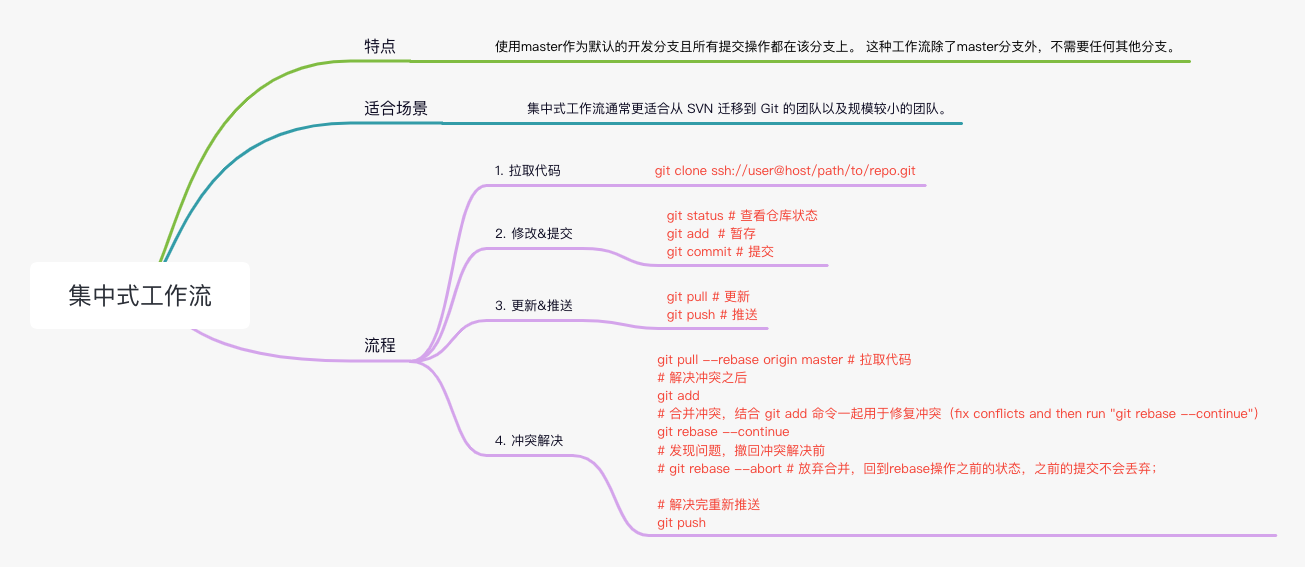
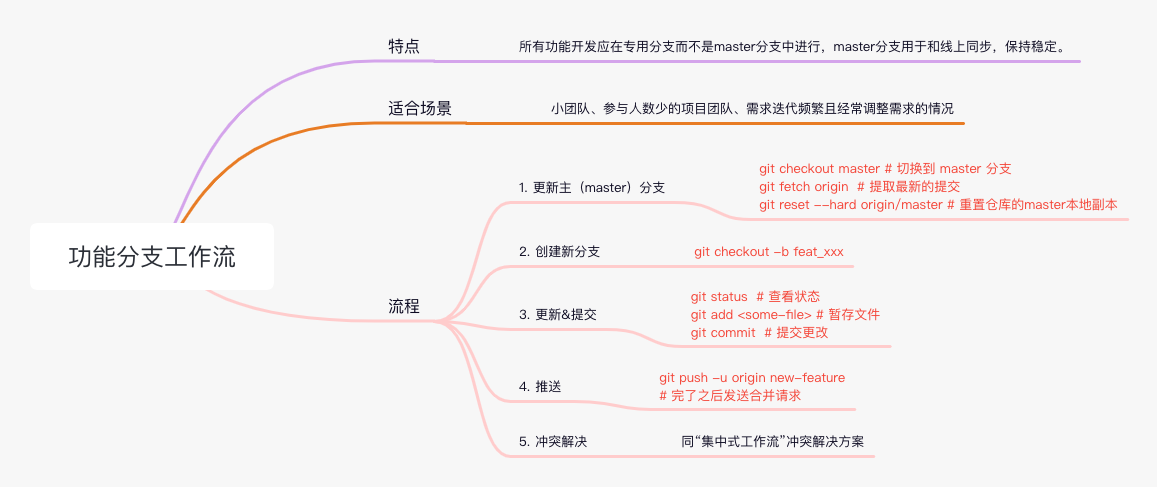
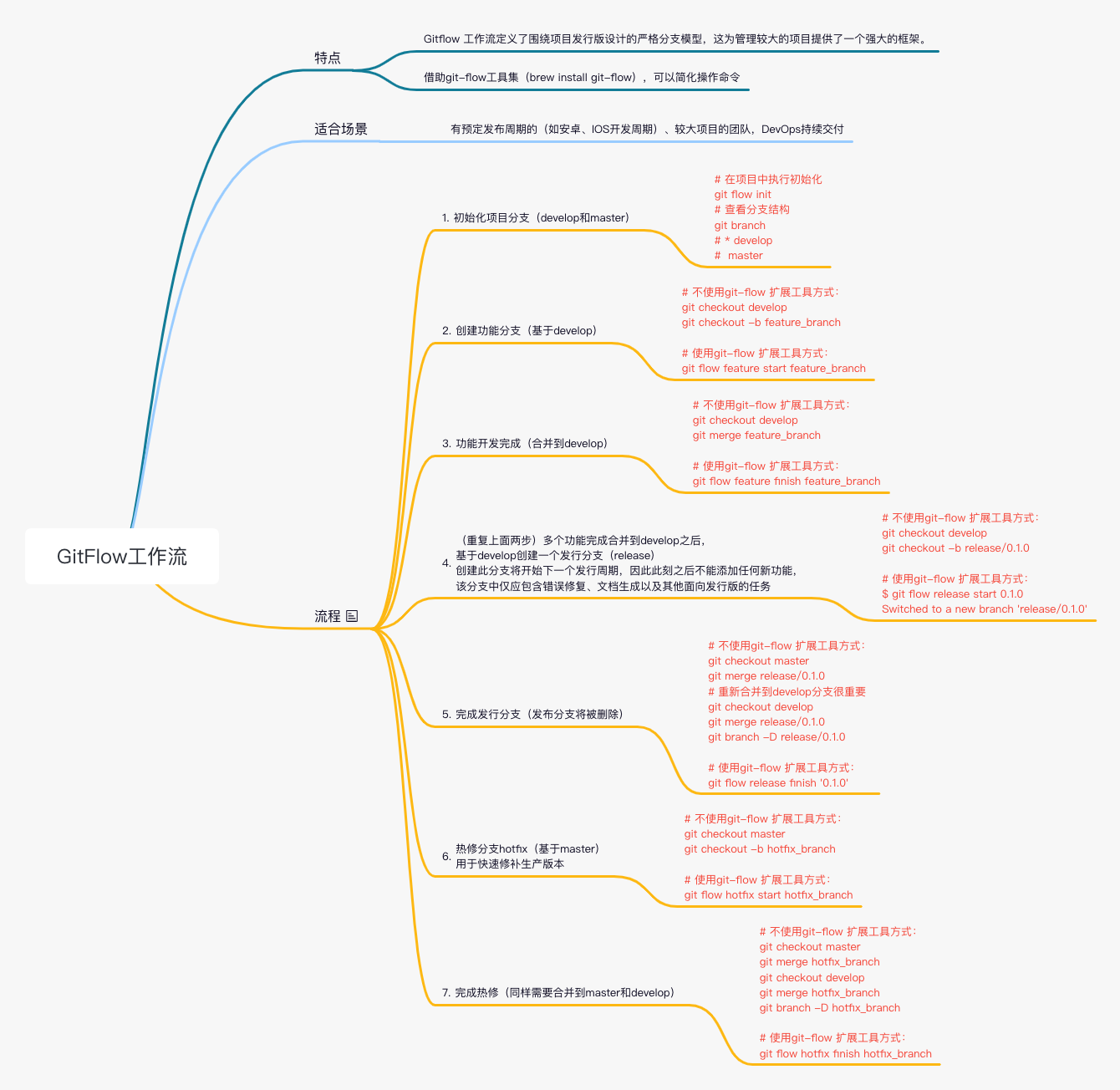
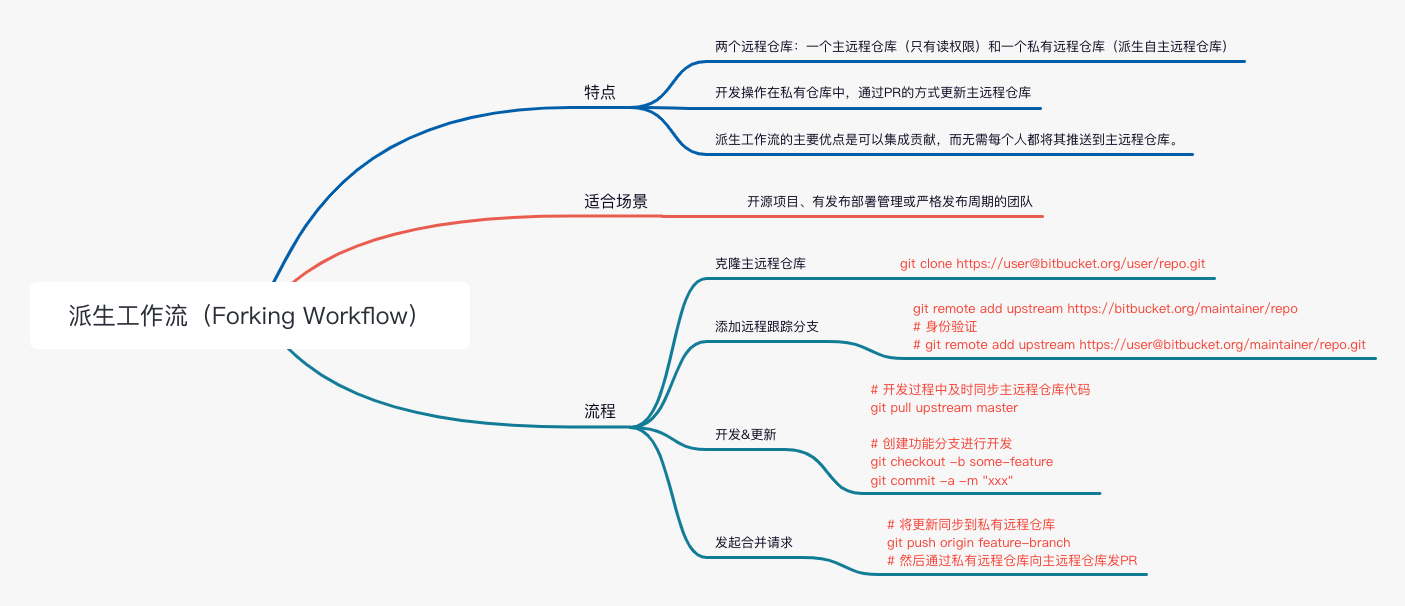
复用类配置:
锚点 Anchors
YAML 有一项名为“锚点”的功能,您可以使用它在整个文档中复制内容。
1 | cache: # 定义一个全局缓存的锚点:global_cache |
&设置锚点的名称 (global_cache),<<意思是“将给定的哈希对象合并到当前哈希对象中”,*包含命名锚点(如:global_cache)。
这个例子的结果是:
1 | cache: # 定义一个全局缓存的锚点:global_cache |
你还可以使用锚点来定义两个服务集合。例如以下示例(test:postgres和test:mysql共享了.job_template的script,但是却有这不同的services,分别定义在了.postgres_services和.mysql_services中):。
1 | .job_template: |
得到的结果将是这样的:
1 | .job_template: |
我们可以看到隐藏的作业被方便地用作模板,并且tags: [postgres] 覆盖了tags: [dev]。
更多锚点的使用示例:
- YAML 锚点用于脚本(script)中:
您可以将 YAML 锚点与 script、before_script 和 after_script 结合使用,以便在多个作业中使用预定义的命令:
1 | .some-script-before: &some-script-before |
- YAML 锚点用于用于变量(variables)中:
使用带有变量的 YAML 锚点在多个作业中重复分配变量。当作业需要特定的变量块时,您还可以使用 YAML 锚点,否则会覆盖全局变量。以下示例显示如何覆盖 GIT_STRATEGY 变量而不影响 SAMPLE_VARIABLE 变量的使用:
1 | # global variables |
引用 !reference
使用 !reference 自定义 YAML 标签从其他作业部分选择关键字配置,并在当前部分中复用它。与锚点不同,您可以使用 !reference 标签来复用通过include引用的配置文件中的配置。
在以下示例中,test作业中重复使用了来自两个不同位置的script和after_script:
setup.yml:
1 | .setup: |
.gitlab-ci.yml:
1 | include: |
在以下示例中,test-vars-1 复用 .vars 中的所有变量,而 test-vars-2 选择特定变量并将其复用为新的 MY_VAR 变量。
1 | .vars: |
您不能重复使用已经包含 !reference 标签的部分。仅支持一层嵌套。
继承 extend
使用extends来复用配置块。它是锚点(Anchor)的替代品,并且更加灵活和可读。您可以使用extends来复用通过include引用的配置文件中的配置。
在以下示例中,rspec 作业使用 .tests 模板作业中的配置。GitLab:
- 根据键执行反向深度合并。
- 将
.tests内容与rspec作业合并。 - 不合并键的值。
1 | .tests: |
rspec作业的结果是:
1 | rspec: |
本例中的 .tests 是一个隐藏作业,但也可以从常规作业中extends配置。
extends 支持多级继承。 虽然您可以使用多达 11 个级别,但是您应该避免使用 3 个以上的级别。以下示例具有两个继承级别:
1 | .tests: |
在 GitLab 12.0 及更高版本中,也可以使用多个父项进行扩展(extends)。
您可以用extends来合并哈希对象但是不能用来合并数组。用于合并的算法是“就近优先原则(closest scope wins)”,因此来自最后一个成员的键总是覆盖其他级别上定义的任何内容。例如:
1 | .only-important: |
结果是:
1 | rspec: |
在上面示例中:
variables合并,但URL:"http://docker-url.internal"覆盖URL:"http://my-url.internal"。tags:['docker']覆盖tags:['production']。script不会合并,但script: ['rake rspec']会覆盖script: ['echo "Hello world!"']。 您可以使用锚点来合并数组。
extends 和 include一起使用:要复用来自不同配置文件的配置,请结合extends 和 include。
在下面的示例中,在 included.yml 文件中定义了一个脚本script。然后,在 .gitlab-ci.yml 文件中,使用extends继承了那部分脚本内容:
included.yml:
1 | .template: |
.gitlab-ci.yml:
1 | include: included.yml |
包含 include
TODO…
总结&注意
使用include关键字时,您不能跨多个文件使用 YAML 锚点。锚点只在定义它们的文件中有效。要复用来自不同 YAML 文件的配置,请使用引用(!reference)或继承(extends)。
英文原文:
锚点 Anchors:https://docs.gitlab.com/ee/ci/yaml/#anchors
引用 !reference:https://docs.gitlab.com/ee/ci/yaml/#reference-tags
继承 extend:https://docs.gitlab.com/ee/ci/yaml/#extends
包含 include:https://docs.gitlab.com/ee/ci/yaml/#include